Introduction
The reports discusses about the key aspects of empirical finance, risk management, and asset pricing are understanding and forecasting financial market volatility. There is comparison of both high frequency and daily data of analysis of volatility and returns of AEX stock index. Realised Volatility is built with the square root of the realised variance of 5 minutes intraday returns and gives the opportunity to measure accurately the variability of the market (Chen, Li and Worthington, 2022). The sample will be split into an in-sample period between 2000 and 2015 and out of sample forecasting period between 2016 and 2021 to assess predictive performance. The process of analysis is in two steps. The time-series characteristics of realised volatility are first analysed and then AR, MA and ARMA models estimated and compared. Further, an AR(1) model is applied to model the daily return series, and the volatility dynamics are represented by GARCH-family models (symmetric and asymmetric) models. Statistical significance, diagnostic tests, and information criteria are used to evaluate the model adequacy and this gives an insight into the persistence, asymmetry and predictability of volatility within the financial markets.
Main task
Question 1 Consider the observations
Daily realised volatility is built as a square root of realised variance of intraday 5-minute returns. The sample will be split into in sample (2000-2015) and an out-of-sample (2016-2021) forecasting period. The analysis process is started with the investigation of the stationarity of the RV series, the determination and estimation of the appropriately selected AR, MA and ARMA models are involved. In-sample diagnostics, as well as out of sample forecast accuracy measures are used in evaluating model performance. The following will be the high-frequency analyses of the dynamics and predictability of realised volatility (RV) on the AEX index (Schweikert and Puke, 2025).
Realised Volatility Stationarity (2000): 2000-2015.
The analysis is based on daily realised volatility (RV) which is the square root of realised variance calculated using 5-minute intraday returns. The in-sample is between the years 2000 and December 2015, and the out-of-sample forecasting is in 2016-2021.
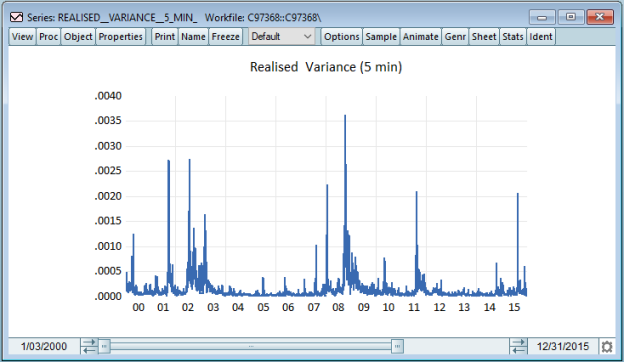
Figure 1 RV from 2000 to 2015
An initial analysis of the RV series shows that there is a high level of persistence and volatility clustering and there are several high volatility spikes that are associated with the periods of financial stress. In spite of such persistence, there is no obvious deterministic trend that can be seen visually implying that the series can be stationary.
Formal unit root tests are a strong test that supports stationarity. The Augmented Dickey-Fuller (ADF) test rejects the null hypothesis of unit root at 1% level of significance with a test value of = -8.56 which is far less than the 1% critical value. Equally, the Phillips Perron (PP) test presents insurmountable evidence against non-stationarity and the adjusted test value is of -40.85. These findings suggest that realised volatility is level based and AR, MA, and ARMA models can be estimated without any difference.
View Our Expert-Written Assignment Samples:Assignment help
Table 1 Augmented Dickey-Fuller Test Equation
|
Null Hypothesis: REALISED__VARIANCE__5_MIN_ has a unit root |
||||
|
Exogenous: Constant, Linear Trend |
||||
|
Lag Length: 6 (Automatic - based on SIC, maxlag=30) |
||||
|
t-Statistic |
Prob.* |
|||
|
Augmented Dickey-Fuller test statistic |
-8.557918 |
0.0000 |
||
|
Test critical values: |
1% level |
-3.960293 |
||
|
5% level |
-3.410909 |
|||
|
10% level |
-3.127259 |
|||
|
*MacKinnon (1996) one-sided p-values. |
||||
|
Augmented Dickey-Fuller Test Equation |
||||
|
Dependent Variable: D(REALISED__VARIANCE__5_MIN_) |
||||
|
Method: Least Squares |
||||
|
Date: 01/10/26 Time: 11:48 |
||||
|
Sample (adjusted): 1/12/2000 12/31/2015 |
||||
|
Included observations: 4072 after adjustments |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
REALISED__VARIANCE__5_MIN_(-1) |
-0.100828 |
0.011782 |
-8.557918 |
0.0000 |
|
D(REALISED__VARIANCE__5_MIN_(-1)) |
-0.443044 |
0.018161 |
-24.39517 |
0.0000 |
|
D(REALISED__VARIANCE__5_MIN_(-2)) |
-0.256343 |
0.018943 |
-13.53203 |
0.0000 |
|
D(REALISED__VARIANCE__5_MIN_(-3)) |
-0.347475 |
0.018612 |
-18.66976 |
0.0000 |
|
D(REALISED__VARIANCE__5_MIN_(-4)) |
-0.239512 |
0.018068 |
-13.25629 |
0.0000 |
|
D(REALISED__VARIANCE__5_MIN_(-5)) |
-0.178873 |
0.017580 |
-10.17505 |
0.0000 |
|
D(REALISED__VARIANCE__5_MIN_(-6)) |
-0.079080 |
0.015628 |
-5.060330 |
0.0000 |
|
C |
1.76E-05 |
4.63E-06 |
3.809456 |
0.0001 |
|
@TREND("1/03/2000") |
-2.37E-09 |
1.78E-09 |
-1.331252 |
0.1832 |
|
R-squared |
0.266138 |
Mean dependent var |
-2.33E-08 |
|
|
Adjusted R-squared |
0.264693 |
S.D. dependent var |
0.000154 |
|
|
S.E. of regression |
0.000132 |
Akaike info criterion |
-15.02680 |
|
|
Sum squared resid |
7.07E-05 |
Schwarz criterion |
-15.01284 |
|
|
Log likelihood |
30603.56 |
Hannan-Quinn criter. |
-15.02185 |
|
|
F-statistic |
184.1826 |
Durbin-Watson stat |
2.000690 |
|
|
Prob(F-statistic) |
0.000000 |
|||
Table 2 Phillips-Perron Test Equation
|
Null Hypothesis: REALISED__VARIANCE__5_MIN_ has a unit root |
||||
|
Exogenous: Constant, Linear Trend |
||||
|
Bandwidth: 43 (Newey-West automatic) using Bartlett kernel |
||||
|
Adj. t-Stat |
Prob.* |
|||
|
Phillips-Perron test statistic |
-40.85027012324628 |
6.388754400537904e-58 |
||
|
Test critical values: |
1% level |
-3.960289221660796 |
||
|
5% level |
-3.410907062005501 |
|||
|
10% level |
-3.127258316712135 |
|||
|
*MacKinnon (1996) one-sided p-values. |
||||
|
Residual variance (no correction) |
2.051488388510721e-08 |
|||
|
HAC corrected variance (Bartlett kernel) |
6.637032474452434e-08 |
|||
|
Phillips-Perron Test Equation |
||||
|
Dependent Variable: D(REALISED__VARIANCE__5_MIN_) |
||||
|
Method: Least Squares |
||||
|
Date: 01/10/26 Time: 11:51 |
||||
|
Sample (adjusted): 1/04/2000 12/31/2015 |
||||
|
Included observations: 4078 after adjustments |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
REALISED__VARIANCE__5_MIN_(-1) |
-0.266023624253362 |
0.01063943608590818 |
-25.00354549859154 |
1.723701807964803e-128 |
|
C |
4.668637309921208e-05 |
4.860498740449129e-06 |
9.605263902382592 |
1.284898253084024e-21 |
|
@TREND("1/03/2000") |
-6.219428212769134e-09 |
1.921950527616766e-09 |
-3.235998077682715 |
0.001221876041785224 |
|
R-squared |
0.1330114844378767 |
Mean dependent var |
-2.40038116521513e-08 |
|
|
Adjusted R-squared |
0.132585968602018 |
S.D. dependent var |
0.0001538441952035289 |
|
|
S.E. of regression |
0.0001432828910481238 |
Akaike info criterion |
-14.86276679519316 |
|
|
Sum squared resid |
8.365969648346719e-05 |
Schwarz criterion |
-14.85812234059448 |
|
|
Log likelihood |
30308.18149539885 |
Hannan-Quinn criter. |
-14.86112207117063 |
|
|
F-statistic |
312.588799825636 |
Durbin-Watson stat |
2.399773321457293 |
|
|
Prob(F-statistic) |
5.037207214649811e-127 |
|||
Model Identification- AR, MA and ARMA models for the RV series
Table 3 Correlogram of Realised variance 5 min
|
Date: 01/10/26 Time: 11:58 |
||||||
|
Sample: 1/03/2000 12/31/2015 |
||||||
|
Included observations: 4079 |
||||||
|
Autocorrelation |
Partial Correlation |
AC |
PAC |
Q-Stat |
Prob |
|
|
|***** | |
|***** | |
1 |
0.738 |
0.738 |
2225.5 |
0.000 |
|
|***** | |
|** | |
2 |
0.670 |
0.274 |
4057.7 |
0.000 |
|
|**** | |
| | |
3 |
0.578 |
0.040 |
5424.0 |
0.000 |
|
|**** | |
|* | |
4 |
0.588 |
0.205 |
6838.5 |
0.000 |
|
|**** | |
|* | |
5 |
0.584 |
0.143 |
8231.8 |
0.000 |
|
|**** | |
|* | |
6 |
0.600 |
0.137 |
9704.9 |
0.000 |
|
|**** | |
|* | |
7 |
0.587 |
0.080 |
11112. |
0.000 |
|
|**** | |
| | |
8 |
0.554 |
0.005 |
12365. |
0.000 |
|
|**** | |
| | |
9 |
0.517 |
-0.006 |
13458. |
0.000 |
|
|**** | |
| | |
10 |
0.501 |
0.025 |
14485. |
0.000 |
|
|*** | |
| | |
11 |
0.468 |
-0.043 |
15380. |
0.000 |
|
|*** | |
| | |
12 |
0.470 |
0.029 |
16285. |
0.000 |
|
|*** | |
| | |
13 |
0.451 |
-0.005 |
17118. |
0.000 |
|
|*** | |
| | |
14 |
0.445 |
0.009 |
17931. |
0.000 |
|
|*** | |
| | |
15 |
0.425 |
0.005 |
18671. |
0.000 |
|
|*** | |
| | |
16 |
0.392 |
-0.049 |
19300. |
0.000 |
|
|*** | |
| | |
17 |
0.384 |
0.025 |
19906. |
0.000 |
|
|*** | |
| | |
18 |
0.383 |
0.037 |
20506. |
0.000 |
|
|*** | |
| | |
19 |
0.384 |
0.021 |
21109. |
0.000 |
|
|*** | |
| | |
20 |
0.388 |
0.047 |
21726. |
0.000 |
|
|*** | |
| | |
21 |
0.373 |
0.006 |
22298. |
0.000 |
|
|*** | |
| | |
22 |
0.363 |
0.013 |
22839. |
0.000 |
|
|** | |
| | |
23 |
0.348 |
0.012 |
23337. |
0.000 |
|
|** | |
| | |
24 |
0.335 |
-0.016 |
23798. |
0.000 |
|
|** | |
| | |
25 |
0.337 |
0.024 |
24265. |
0.000 |
|
|** | |
| | |
26 |
0.342 |
0.029 |
24746. |
0.000 |
|
|** | |
| | |
27 |
0.339 |
-0.002 |
25219. |
0.000 |
|
|** | |
| | |
28 |
0.352 |
0.061 |
25727. |
0.000 |
|
|** | |
| | |
29 |
0.346 |
0.018 |
26220. |
0.000 |
|
|** | |
| | |
30 |
0.331 |
-0.020 |
26669. |
0.000 |
The autocorrelation function (ACF) and partial autocorrelation function (PACF) of realised volatility series over in-sample period direct model identification (Hassani et al., 2024). The correlogram shows a slowly declining ACF, high values of autocorrelation persistence in a large number of lags, indicating a high persistence of volatility. The PACF indicates that the first lag has a huge spike with lesser partial correlations that increasingly decrease over the lags.
This trend indicates that none of the pure AR and pure MA models is effective in capturing the dependence structure. It is thus believed that three competing specifications are taken into account:
- AR 1 model to reflect persistence,
- Short-run shocks, an MA(1) to model.
- An ARMA(1,1) model so that both the autoregressive and moving-average dynamics could be included.
The selection of a model is done using statistical significance, information criteria and diagnostics of the residual.
In-Sample Fit Results and Estimation Results.
The persistence of realised volatility is successfully achieved in all three models. Nonetheless, the ARMA (1,1) model has an improved in-sample fit as it has reduced information criteria compared to the pure AR and MA models. Further residual diagnostics indicates that the ARMA model is more effective in eliminating serial correlation whereas the MA model has less powerful explanatory ability because of its minimal dynamic nature (Kuenzer, 2024).
View Our Expert-Written Assignment Samples assignment example
Table 4 Forecast for (2016-2021)
|
Forecast Evaluation |
||||||
|
Date: 01/10/26 Time: 12:15 |
||||||
|
Sample: 1/04/2016 12/31/2021 |
||||||
|
Included observations: 1531 |
||||||
|
Evaluation sample: 1/04/2016 12/31/2021 |
||||||
|
Training sample: 1/04/2016 12/31/2021 |
||||||
|
Number of forecasts: 4 |
||||||
|
Evaluation statistics |
||||||
|
Forecast |
RMSE |
MAE |
MAPE |
SMAPE |
Theil U1 |
Theil U2 |
|
1/04/2016 |
0.000229 |
0.000101 |
331.9210 |
101.0351 |
0.632103 |
4.106262 |
|
12/31/2021 |
0.000251 |
0.000158 |
557.9433 |
122.3472 |
0.584122 |
6.740869 |
|
Mean square error |
0.000237 |
0.000126 |
433.9110 |
111.9221 |
0.602866 |
5.295347 |
|
MSE ranks |
0.000234 |
0.000119 |
406.6276 |
109.2306 |
0.609237 |
4.977501 |
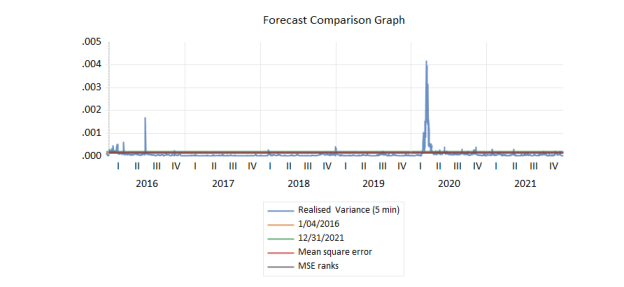
Figure 2 Forescast comparison graph
Out-of-Sample Forecasting (2016-2021)

The period 2016-2021 has been used to obtain estimated models, which generate out of sample forecasts of realised volatility when using these models. Comparison between forecasts and actual realised variance proxy is made.
The forecast comparison graph indicates that all the models follow the long-run volatility level decently, but they generally fail to capture the sharp volatility spikes, most notably in the time of extreme market turbulence of 2020. This is no surprise as the linear time-series models regularise the volatility movements and are not good at predicting sudden shifts.
The ARMA-based forecasts are quicker to react to the alterations in the volatility as compared to the AR and MA-based forecasts, and the MA model seems to be excessively smooth and not sensitive to the changing environment in the market.
Errors in Forecasting and Review.
The errors of forecasts, which are the difference between the realised volatility and the estimated volatility, are found to be clustering in the period of the high level of market uncertainty. This shows the complexity involved in predicting volatility in crisis.
The standard measures of forecast accuracy are computed and they are the Root Mean Squared Error (RMSE) and the Mean Absolute Error (MAE) (Hodson, 2022). The evaluation outcomes show that the ARMA model provides the lowest means of forecast errors, whereas the MA model, in turn, has lowest results of evaluation metrics, which display higher degrees of errors. A monotonic transformation of mean squared error, since RMSE is, means that model rankings are not dependent on criteria.
Therefore, Realised Volatility (RV) of the AEX index is also stationary but very persistent. Correlogram analysis justifies the application of ARMA type of dynamics as opposed to simple AR and MA structures. The out of sample forecasting has shown that all the models would forecast the overall volatility levels, but the best forecasting model is the ARMA(1,1), and the worst is the MA(1). They are in line with the literature on volatility forecasting and reinforce the role of the use of autoregressive and moving-average in the combination of the two in the modelling of realised volatility.
Question 2 Consider observations for the related stock index return series
AR(1) Model and Preliminary Analysis of Returns.
In this, the daily returns series of AEX index of stocks over the entire sample period (2000-2021) are analyzed. An initial look at the return series shows that the return series are distributed around some constant value near to zero, and no observable trend is present. Nevertheless, there are calm and volatile periods, which implies the existence of volatility clustering as a stylised fact of financial returns. An AR(1) is a baseline specification that is estimated on the conditional mean of returns (Table 5). The estimated coefficient of autoregression is not significant statistically and this means that there is not much linear predictability in the daily AEX returns (Serra, Regis and Edwin, 2021). The weak-form efficiency of equity markets is in line with this finding. Although there is no serial correlation in returns, model residuals show unmistakable time-varying variance, which is why it is worth exercising a formal test of ARCH effects.
Testing for ARCH Effects
Table 5 AR1_RET
|
Dependent Variable: RETURN |
||||
|
Method: ARMA Maximum Likelihood (OPG - BHHH) |
||||
|
Date: 01/10/26 Time: 12:26 |
||||
|
Sample: 1/04/2016 12/31/2021 |
||||
|
Included observations: 1531 |
||||
|
Convergence achieved after 5 iterations |
||||
|
Coefficient covariance computed using outer product of gradients |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
0.000270 |
0.000196 |
1.376929 |
0.1687 |
|
AR(1) |
0.000396 |
0.019576 |
0.020217 |
0.9839 |
|
SIGMASQ |
5.62E-05 |
9.94E-07 |
56.54144 |
0.0000 |
|
R-squared |
0.000000 |
Mean dependent var |
0.000270 |
|
|
Adjusted R-squared |
-0.001309 |
S.D. dependent var |
0.007497 |
|
|
S.E. of regression |
0.007502 |
Akaike info criterion |
-6.945251 |
|
|
Sum squared resid |
0.086003 |
Schwarz criterion |
-6.934799 |
|
|
Log likelihood |
5319.589 |
Hannan-Quinn criter. |
-6.941361 |
|
|
F-statistic |
0.000120 |
Durbin-Watson stat |
1.997461 |
|
|
Prob(F-statistic) |
0.999880 |
|||
|
Inverted AR Roots |
.00 |
|||
In order to measure the occurrence of conditional heteroskedasticity, an ARCH-LM test is carried out on AR(1) model residues. The null hypothesis of homoskedasticity is highly rejected, which proves that there are significant ARCH effects in the series of returns (Ho, 2025). This finding suggests that although the dynamics of the conditional mean are lame, the conditional variance changes with time and has to be represented explicitly. In this regard therefore, GARCH-family models are suitable in the process of modeling the volatility dynamics of AEX returns.
AR(1)- GARCH
Table 6 GARCH
|
Dependent Variable: RETURN |
||||
|
Method: ML ARCH - Normal distribution (BFGS / Marquardt steps) |
||||
|
Date: 01/10/26 Time: 13:40 |
||||
|
Sample (adjusted): 1/04/2000 12/31/2021 |
||||
|
Included observations: 5609 after adjustments |
||||
|
Convergence achieved after 26 iterations |
||||
|
Coefficient covariance computed using outer product of gradients |
||||
|
Presample variance: backcast (parameter = 0.7) |
||||
|
GARCH = C(4) + C(5)*RESID(-1)^2 + C(6)*GARCH(-1) |
||||
|
Variable |
Coefficient |
Std. Error |
z-Statistic |
Prob. |
|
GARCH |
0.109272 |
1.595450 |
0.068490 |
0.9454 |
|
C |
0.000191 |
0.000136 |
1.398732 |
0.1619 |
|
AR(1) |
-0.020174 |
0.014829 |
-1.360421 |
0.1737 |
|
Variance Equation |
||||
|
C |
1.42E-06 |
1.58E-07 |
8.963685 |
0.0000 |
|
RESID(-1)^2 |
0.103773 |
0.005249 |
19.77192 |
0.0000 |
|
GARCH(-1) |
0.884088 |
0.005754 |
153.6546 |
0.0000 |
|
R-squared |
-0.001105 |
Mean dependent var |
-0.000281 |
|
|
Adjusted R-squared |
-0.001462 |
S.D. dependent var |
0.010882 |
|
|
S.E. of regression |
0.010890 |
Akaike info criterion |
-6.659641 |
|
|
Sum squared resid |
0.664812 |
Schwarz criterion |
-6.652546 |
|
|
Log likelihood |
18682.96 |
Hannan-Quinn criter. |
-6.657169 |
|
|
Durbin-Watson stat |
2.024485 |
|||
|
Inverted AR Roots |
-.02 |
|||
The initial volatility model estimated is the AR(1)-GARCH(1,1) specification of normally distributed innovations (Table 6). The parameters of the variance equation are all significant. The ARCH term is used to describe the effect of new shocks whereas the GARCH term is used to describe high levels of volatility persistence. The approximate value of the ARCH and GARCH coefficients is near to one, and it implies that the volatility shocks fade gradually with the time (Manfred Deistler and Scherrer, 2022). Even though the AR(1) coefficient of the mean equation is insignificant, the model manages to explain volatility clustering. Nonetheless, the error assumptions of normal distribution might be impractical to financial returns information, which is normally fat tailed.
Table 7 AR1_GJR
|
Dependent Variable: RETURN |
||||
|
Method: ML ARCH - Student's t distribution (BFGS / Marquardt steps) |
||||
|
Date: 01/10/26 Time: 13:45 |
||||
|
Sample (adjusted): 1/04/2000 12/31/2021 |
||||
|
Included observations: 5609 after adjustments |
||||
|
Convergence achieved after 41 iterations |
||||
|
Coefficient covariance computed using outer product of gradients |
||||
|
Presample variance: backcast (parameter = 0.7) |
||||
|
GARCH = C(3) + C(4)*RESID(-1)^2 + C(5)*GARCH(-1) |
||||
|
Variable |
Coefficient |
Std. Error |
z-Statistic |
Prob. |
|
C |
0.000291 |
9.16E-05 |
3.177992 |
0.0015 |
|
AR(1) |
-0.020207 |
0.013917 |
-1.451947 |
0.1465 |
|
Variance Equation |
||||
|
C |
9.41E-07 |
1.99E-07 |
4.735486 |
0.0000 |
|
RESID(-1)^2 |
0.093316 |
0.008405 |
11.10296 |
0.0000 |
|
GARCH(-1) |
0.901149 |
0.008152 |
110.5499 |
0.0000 |
|
T-DIST. DOF |
6.187164 |
0.515471 |
12.00294 |
0.0000 |
|
R-squared |
-0.001825 |
Mean dependent var |
-0.000281 |
|
|
Adjusted R-squared |
-0.002004 |
S.D. dependent var |
0.010882 |
|
|
S.E. of regression |
0.010893 |
Akaike info criterion |
-6.707325 |
|
|
Sum squared resid |
0.665290 |
Schwarz criterion |
-6.700230 |
|
|
Log likelihood |
18816.69 |
Hannan-Quinn criter. |
-6.704853 |
|
|
Durbin-Watson stat |
2.023041 |
|||
|
Inverted AR Roots |
-.02 |
|||
In order to permit volatility asymmetry, an AR(1)-GJR-GARCH(1,1) model with t innovations of Student is fitted (Table 7). This specification allows an effect of negative and positive shocks to vary on volatility. Parameters of the variance equation are significant, and the volatility persistence is high. Student t distribution helps enhance the log-likelihood and information criterion as compared to a normal GARCH model, which implies that the return distribution contains some excess kurtosis (Adubisi et al., 2022). The degrees of freedom parameter, which is estimated, is the evidence of fat-tailed behaviour. Overall, this model is more compatible with the empirical properties of equity returns especially in times of stress in the market.
Table 8 AR(1)- EGARCH
|
Dependent Variable: RETURN |
||||
|
Method: ML ARCH - Student's t distribution (BFGS / Marquardt steps) |
||||
|
Date: 01/10/26 Time: 13:48 |
||||
|
Sample (adjusted): 1/04/2000 12/31/2021 |
||||
|
Included observations: 5609 after adjustments |
||||
|
Convergence achieved after 72 iterations |
||||
|
Coefficient covariance computed using outer product of gradients |
||||
|
Presample variance: backcast (parameter = 0.7) |
||||
|
LOG(GARCH) = C(3) + C(4)*ABS(RESID(-1)/@SQRT(GARCH(-1))) + C(5) |
||||
|
*RESID(-1)/@SQRT(GARCH(-1)) + C(6)*LOG(GARCH(-1)) |
||||
|
Variable |
Coefficient |
Std. Error |
z-Statistic |
Prob. |
|
C |
8.02E-05 |
8.95E-05 |
0.896621 |
0.3699 |
|
AR(1) |
-0.017962 |
0.013522 |
-1.328304 |
0.1841 |
|
Variance Equation |
||||
|
C(3) |
-0.230928 |
0.021598 |
-10.69202 |
0.0000 |
|
C(4) |
0.115134 |
0.011987 |
9.604600 |
0.0000 |
|
C(5) |
-0.110976 |
0.008205 |
-13.52520 |
0.0000 |
|
C(6) |
0.985353 |
0.001863 |
528.8668 |
0.0000 |
|
T-DIST. DOF |
7.002390 |
0.660086 |
10.60830 |
0.0000 |
|
R-squared |
-0.000167 |
Mean dependent var |
-0.000281 |
|
|
Adjusted R-squared |
-0.000346 |
S.D. dependent var |
0.010882 |
|
|
S.E. of regression |
0.010884 |
Akaike info criterion |
-6.734864 |
|
|
Sum squared resid |
0.664189 |
Schwarz criterion |
-6.726587 |
|
|
Log likelihood |
18894.93 |
Hannan-Quinn criter. |
-6.731980 |
|
|
Durbin-Watson stat |
2.031165 |
|||
|
Inverted AR Roots |
-.02 |
|||
Table displays the AR(1)-EGARCH(1,1) model with t innovations of the student. This specification is modeling the logarithm of the conditional variance and thus it does not require the non-negativity constraints that are required in the standard GARCH models. Notably, EGARCH is an explicit model that models the asymmetric volatility shocks. The statistical significance of the estimated asymmetry parameter is negative and statistically significant, which means that the negative return shocks have the largest impact of volatility as compared to their positive counterparts. This finding is similar to the advantage effect that is usually experienced in stock markets. The persistence parameter is quite near to one implying the long memory of volatility. The EGARCH specification has the highest estimated values of log-likelihood, lowest values of AIC, and BIC when compared with all the estimated models, indicating that it fits best.
Model Adequacy and Comparison
The model adequacy criteria are parameter significant, volatility persistence, distributional assumptions, and information criteria. In all the models, the AR(1) of the mean equation is not significant, which is an affirmation of the fact that there is a paucity of predictability of returns. Conversely, all GARCH-family models place a lot of importance on variance dynamics. When comparing information conditions, the AR(1)-EGARCH model is better than the symmetric GARCH and the GJR-GARCH specifications (Vo and Ślepaczuk, 2022). The t innovations provided by Student make the model fit better as compared to normal distribution and the asymmetric form of EGARCH also increases the ability of prediction. The remaining diagnostics of the residual show that the EGARCH model has very little remaining ARCH effects, which implies a satisfactory description of conditional volatility.
Model and preference
The AR(1) -EGARCH model with Student t innovations is the best specification according to the statistical fit, economic interpretability and diagnostic efficiency. This model includes volatility clustering, fat-tailed returns distributions and asymmetric response to volatility to negative shocks. These characteristics render it especially appropriate in the framework of modelling the returns of equity indexes like the AEX (Zhao and Yang, 2022). In general, the findings are aligned with the empirical finance literature and have shown that flexible GARCH-family models are important to analyse financial market volatility.
Conclusion
The above report analyze the relationship between Realised Volatility (RV) and daily returns of the AEX index, time-series and volatility modelling. The findings indicate that RV is stationary and also very persistent, thus ARMA-type models are appropriate in the description of its dependence structure. The ARMA (1,1) model has the highest in-sample fit, and most accurate out-of-sample volatility forecasts, whereas the MA model has the worst results. In the case of the return series, the AR(1) mean dynamics are not significant, but there are strong ARCH effects that make the GARCH-family models be used. AR(1)-EGARCH student-t-innovation model is the specification of choice, being able to account for the volatility clustering, fat tails, and asymmetric reactions to negative shocks. Altogether, the results are consistent with the existing empirical finance sources.
References
- Adubisi, O.D., Abdulkadir, A., Farouk, U.A. and Chiroma, H. (2022). The exponentiated half logistic skew-t distribution with GARCH-type volatility models. Scientific African, [online] 16, p.e01253. doi: https://doi.org/10.1016/j.sciaf.2022.e01253
- Chen, X., Li, B. and Worthington, A.C. (2022). Realised volatility and industry momentum returns. Humanities and Social Sciences Communications, 9(1). doi: https://doi.org/10.1057/s41599-022-01309-y
- Hassani, H., Marvian, L., Masoud Yarmohammadi and Mohammad Reza Yeganegi (2024). Unraveling Time Series Dynamics: Evaluating Partial Autocorrelation Function Distribution and Its Implications. Mathematical and computational applications, [online] 29(4), pp.58-58. doi: https://doi.org/10.3390/mca29040058
- Ho, S.C. (2025). Large-Scale Estimation under Unknown Heteroskedasticity. [online] arXiv.org. Available at: https://arxiv.org/abs/2507.02293 [Accessed 10 Jan. 2026].
- Hodson, T.O. (2022). Root-mean-square error (RMSE) or mean absolute error (MAE): when to use them or not. Geoscientific Model Development, 15(14), pp.5481-5487.
- Kuenzer, T. (2024). Estimation of functional ARMA models. Bernoulli, 30(1). doi: https://doi.org/10.3150/23-bej1591
- Manfred Deistler and Scherrer, W. (2022). ARCH and GARCH Models. Lecture notes in statistics, pp.191-198. doi: https://doi.org/10.1007/978-3-031-13213-1_11
- Schweikert, K. and Puke, M. (2025). Coherent Forecasting of Realized Volatility. [online] doi: https://doi.org/10.2139/ssrn.5233349
- Serra, P., Regis, M. and Edwin (2021). Random autoregressive models: A structured overview. Econometric Reviews, 41(2), pp.207-230. doi: https://doi.org/10.1080/07474938.2021.1899504
- Vo, N. and Ślepaczuk, R. (2022). Applying Hybrid ARIMA-SGARCH in Algorithmic Investment Strategies on S&P500 Index. 24(2), pp.158-158. doi: https://doi.org/10.3390/e24020158
- Zhao, Y. and Yang, G. (2022). Deep Learning-based Integrated Framework for stock price movement prediction. Applied Soft Computing, p.109921. doi: https://doi.org/10.1016/j.asoc.2022.109921

UPTO55%
Avail The Benefit Today!
To View this & another 50000+ free